
معرفی کتابخانه easyPubMed در R و آموزش استخراج داده از پایگاه پابمد
easyPubMed یک کتابخانه در R است که امکان جستجو و بازیابی رکوردهای پابمد در فرمت XML و TXT را به راحتی فراهم میکند. به وسیله این کتابخانه میتوان حجم زیادی از رکوردها را از پایگاه پابمد جستجو و به راحتی آنها را دانلود کرد. این کتابخانه همچنین امکاناتی برای پردازش رکوردها و استخراج دادههای مورد نظر (مانند دادههای خاص در مورد نویسندگان مقالات) را فراهم میکند. در ادامه مطلب به نحوه نصب کتابخانه، جستجو در پابمد، دانلود و پردازش دادهها در easyPubMed میپردازیم.
نصب کتابخانه ایزی پابمد
این نرم افزار به صورت یک کتابخانه برای زبان برنامه نویسی R ارائه شده، در نتیجه شما نمیتونید مستقیما اون رو اجرا کنید و باید از محیط نرم افزار RStudio برای اجرای این کتابخانه استفاده کنید. مراحل نصب و راه اندازی نرم افزار:
1- نرم افزار RStudio رو از این آدرس یا هر جای دیگه که دوست دارید دانلود و نصب کنید.
2- RStudio رو باز کنید و در کنسول، کد زیر رو مطابق تصویر وارد کنید و سپس اینتر بزنید. با اینکار میتونید کتابخانه ایزی پابمد رو از مخزن CRAN دانلود و نصب میکنید (حتما باید به اینترنت وصل باشید)
install.packages("easyPubMed")
در صورت نصب موفق کتابخانه ایزی پابمد پیغام (package ‘easyPubMed’ successfully unpacked and MD5 sums checked) رو مشاهده میکنید.
جستجو در پابمد از طریق کتابخانه ایزی پابمد
برای اینکه آموزش کار با ایزی پابمد رو بصورت عملی با هم یاد بگیریم، سعی میکنم آموزش رو منطبق با یک مسئله پیش ببرم. فرض کنید قصد داریم یه پژوهش در مورد مقالات رترکتشده ایران در پایگاه پابمد انجام بدیم. برای بازیابی این مقالات به راحتی با استراتژی جستجوی زیر در پایگاه پابمد میتونیم مقالات مورد نظرمون رو دانلود کنیم:
iran[ad] AND retracted[sb]
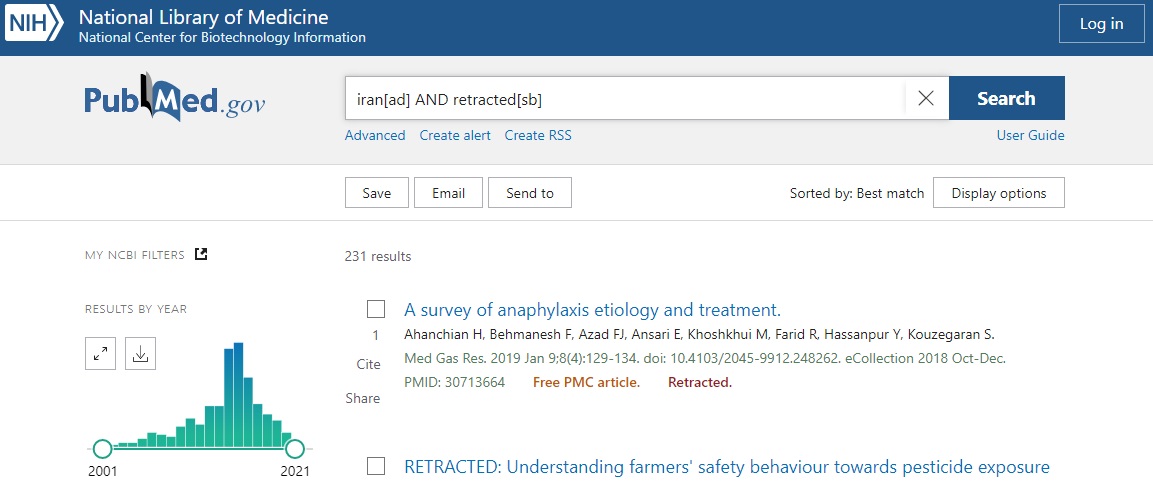
میتونیم به راحتی این مقالات رو از طریق Send to دانلود کنیم و در نرم افزارهایی مثل Endnote و یا Vosviewer استفاده کنیم.
حالا فرض کنید اطلاعاتی که نیاز داریم یکم خاصتر از این حرفهاست. مثلا به اطلاعات نام کوچک نویسنده اول مقالات رترکتشده ایرانی در پابمد احتیاج داریم! استخراج چنین اطلاعاتی کار آسونی نیست و اگر با کتابخانه ایزی پابمد آشنایی نداشته باشیم، احتمالا تنها راهی جلومون هست ایجاد یه فایل اکسل و کپی کردن تک تک اسامی نویسندگان به صورت دستی در فایل اکسل باشه!
در این آموزش سعی میکنیم فرایند جستجو، دانلود و پردازش رکوردها در ایزی پابمد رو بر اساس مثال فوق با همدیگه انجام بدیم.
1- برای شروع به کار با کتابخانه ایزی پابمد ابتدا باید این کتابخانه رو در محیط R فراخوانی کنیم. بدین منظور کد زیر رو در کنسول R بنویسید و اینتر بزنید.
library(easyPubMed)
2- حالا که کتابخونه فراخوانی شده، نیاز هست که یه متغیر تعریف کنیم و استراتژی جستجومون رو در اون متغیر قرار بدیم. اگه بخوایم این متغیر رو برای استراتژی جستجوی مقالات رترکت شده ایرانی ایجاد کنیم، میتونیم از کد زیر استفاده کنیم:
new_PM_query <-'iran[ad] AND retracted[sb]'
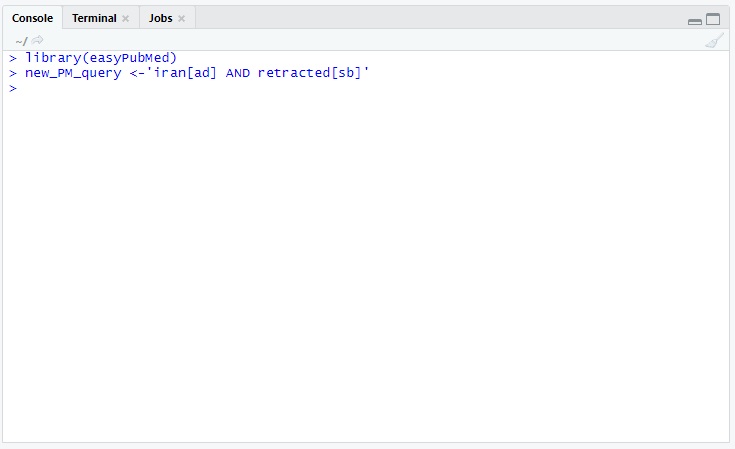
شیوه نگارش استراتژی جستجو دقیقا همونی هست که در جستجوی پیشرفته پابمد استفاده میشه. نکته مهم اینه که در تعریف متغیر باید استراتژی جستجو رو در سینگل کوتیشن 'استراتژی' قرار بدید.
3- حالا باید به ایزی پابمد بگیم که این کوئری رو در پابمد اجرا کنه و نتایج رو در فرمت xml یا txt برای ما دانلود کنه و در یک متغییر جدید بریزه. این کار رو میتونید با کد زیر انجام بدید:
out.A <- batch_pubmed_download(pubmed_query_string = new_PM_query, format="txt", dest_file_prefix = "Iranian_Retracted_Article")
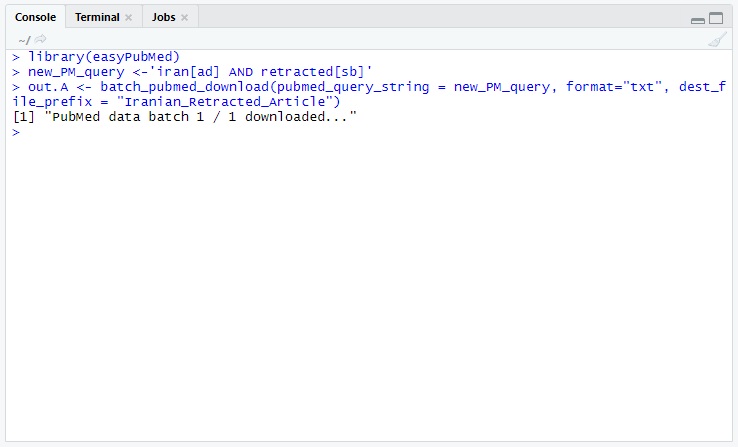
به وسیله کد فوق، ما یه متغیر به اسم out.A ایجاد کردیم و درش متغیر سرچ استراتژیمون رو فراخوانی کردیم و گفتیم رکوردهاش رو دانلود کن و با نام Iranian_Retracted_Article و فرمت txt ذخیره کن. مقدار فرمت رو میتونید در صورت نیاز xml هم قرار بدید.
این کار بسته به تعداد رکوردهایی که فراخوانی کردیم و سرعت اینترنتمون امکان داره چند دقیقهای طول بکشه.
تا اینجای کار ما مقالات رترکت شده ایرانی رو جستجو و دانلود کردیم. حالا وارد مرحله پردازش این مقالات میشیم.
پردازش رکوردهای پابمد
حالا باید از ایزی پابمد درخواست کنیم اطلاعاتی که مد نظرمون هست رو برامون بازیابی کنه. برای این کار، ایزی پابمد چندین تابع داره که برای آشنایی با انواع اونها میتونید به راهنمای این کتابخانه سر بزنید. طبق مسئلهای که داشتیم، ما میخواستیم که اسامی نویسندگان اول مقالات رو استخراج کنیم. برای استخراج نویسندگان مقالات، تابع table_articles_byAuth میتونه بدردمون بخوره. در ادامه با استفاده از این تابع، اسامی نویسندگان اول مقالات رترکت شده ایرانی رو استخراج میکنیم.
4- برای استخراج اسامی نویسندگان، متغیری تعریف میکنیم و در اون متغیر با استفاده از تابع table_articles_byAuth، متغیری که در مرحله 3 داده های پابمد رو درش ذخیره کرده بودیم فراخوانی میکنیم. کد زیر این کار رو انجام میده:
new_PM_df <- table_articles_byAuth(pubmed_data = out.A, included_authors = "first", max_chars = 0)
در کد فوق، پارامتر included_authors میتونه یکی از سه حالت “first”, “last”, “all” رو بپذیره. اگه مثل کد بالا first رو انتخاب کرده باشید، این کد نام نویسنده اول مقالات رو براتون استخراج میکنه. اگه last رو انتخاب کنید، نویسنده آخر و اگر all رو انتخاب کنید اطلاعات کامل تمام نویسنده ها رو براتون استخراج میکنه.
5- حالا اگه بخوایم دادههایی که استخراج کردیم رو مشاهده کنیم، کافیه که اونها رو به فرمت csv ذخیره کنیم تا بتونیم اطلاعات مورد نظرمون رو در نرم افزار اکسل باز کنیم. برای این کار کافیه کد زیر رو بزنید و مسیری که میخواید فایل csvتون ذخیره بشه رو بهش بگید (در مثال زیر دسکتاپ کامپیوتر رو انتخاب کردم):
write.csv(new_PM_df,"C:\\Users\\Mansourzadeh\\Desktop\\First.csv", row.names = FALSE)
الان به همین راحتی شما یه فایل csv دارید که حاوی اطلاعات نویسندگان اول مقالات رترکت شده ایرانی در پایگاه پابمد هست.
نتیجهگیری
در این آموزش یاد گرفتیم که چطور کتابخانه ایزی پابمد رو نصب کنیم، استراتژی جستجومون رو درش اجرا کنیم و دادههای مورد نظرمون رو ازش استخراج کنیم. فرایند کار با ایزی پابمد به همین راحتیه. ولی شما همیشه به اطلاعات نویسنده اول مقالات نیاز ندارید! طیف وسیعی از دادهها (مثل "pmid", "doi", "title", "abstract", "year", "month", "day", "jabbrv", "journal", "lastname", "firstname", "address", "email") رو میشه به وسیله این کتابخونه از رکوردهای پابمد استخراج کرد. به طور مثال با نوشتن 5 خط کد میتونید به راحتی ایمیلهای نویسندگان یه مجموعه مقالات رو استخراج کنید.
منابع برای مطالعه بیشتر
برای اطلاعات بیشتر بد نیست سری به سایت کتابخانه easyPubMed بزنید. در این سایت اطلاعات بسیار خوب همراه با مثال های کاربردی از نحوه استخراج اطلاعات از پایگاه پابمد ذکر شده که شما رو از هر راهنمای دیگه ای بی نیاز میکنه.
همچنین یک دستنامه مختصر و جمع و جور برای این کتابخانه نوشته شده که میتونید از این لینک اون رو دانلود کنید.







ممنون آقای دکتر منصورزاده عزیز.
همواره موفق و پیروز باشید